Transforming Channel Partner Search at CARS24
Introduction
At Cars24, enabling our channel partners to swiftly find the right car is crucial. From large inventories to specialized categories like premium or scrapcars, we needed a filtering system that could seamlessly handle diverse use cases. Our initial architecture, however, struggled with scaling issues — no dynamic facets, no saved filters, and a brittle approach to constructing Elasticsearch queries.
In this article, we’ll walk through why we revamped our filter infrastructure, what challenges we faced, and how we ultimately leveraged Lucene Query Syntax, an Abstract Syntax Tree (AST) approach, and config-driven aggregations to power every filter — from user’s search carousels to inline checkboxes. By the end, you’ll see how one “language” — Lucene — bridged the frontend and backend to deliver a flexible and future-proof solution.
Key Concepts
Filters & Facets
Filters and facets form the foundation of our search experience. Filters act as precise selectors, letting users narrow results by specific criteria (Make: BMW, Price: 10L). Meanwhile, facets provide real-time visibility into available options before selection — showing “A4 (16 cars)” vs “A6 (11 cars)” directly in the UI.
Aggregations
Our system leverages Elasticsearch aggregations to compute essential metrics across filtered datasets. This powers insights like:
- Average price per brand
- Cars available per model
- Distribution across fuel types
- Price ranges within specific locations
Operation Association
Search logic combines filters through two primary operations:
AND → Must match all criteria BMW AND Petrol = Only BMW cars with petrol engines OR → Match any criteria Mumbai OR Thane = Cars from either location
Saved Filters
To enhance efficiency, channel partners can save frequently-used search combinations. We ensure consistency through hash-based storage:
Make:BMW AND Model:3Series Model:3Series AND Make:BMW
Abstract Syntax Tree (AST)
Complex filter combinations are represented as tree structures:
AND
├── make:BMW └── OR ├── model:3Series └── price:[20L TO 30L] This enables precise parsing, storage, and reconstruction of search queries.
Lucene Query Syntax
Our system leverages Elasticsearch’s native Lucene syntax for powerful search capabilities:
# Core Features Fuzzy Search → model:Camry~2 Wildcards → model:Cor* Ranges → price:[20L TO 30L] Boost Terms → make:BMW² Regex → features:/.*sunroof.*/ # Complex Example (+make:BMW^2 AND (model:3Series~2 OR price:[20L,30L]) AND features:/.*sunroof.*/ AND NOT color:Red)
Challenges with the Old Architecture
No Dynamic Facets
The old filters lacked real-time counts. For example, picking Audididn’t tell you how many A4or A6cars were left without applying the filter first.
Hardcoded Query Generation
Our backend built Elasticsearch bool queries from complex JSON objects and “enums” — any new filter or advanced query (like fuzzy or range) required code changes in multiple places.
Limited Use Cases
We had to hack in queries for specialized scenarios (like scrap=true for scrap cars). Adding new categories or filter logic was cumbersome.
No Saved Filters
Partners repeated the same filter combos daily (e.g. make:Maruti Owner:1st), but we had no way to save or reuse them.
Poor Scalability
As we added more filter categories (Fuel Type, Year, Transmission, etc.), the overhead of manual updates, code merges, and bug fixes grew exponentially.
Problem Statement & Vision: Creating a Future-Ready Filter Architecture
Before diving into our approach for generating Elasticsearch queries with aggregations, let’s look at the core challenges we aimed to solve:
- Universal Filter Onboarding
- We needed a framework that could easily accommodate any type of filter — be it a Range filter (price, year), a Single Selection filter (fuel type, car make), or an N-layer hierarchical filter (make → model → variant).
- The ultimate goal: let teams add or update filters via CRUD operations — no more patchwork code changes — as long as the value is present in Elasticsearch.
2. Extending to Advanced, Dynamic Filters
- Some filters aren’t just “present” in Elasticsearch as static fields. They may require runtime evaluation — for instance, Painless scripts that calculate derived values (e.g., custom computed attributes).
- Our architecture should be flexible enough to plug in these advanced concepts without rewriting the entire filter subsystem.
3. Category-Level Config
- As the platform grows, we might want to offer different filter sets for different categories (e.g., premium cars vs. scrap cars, or auctions vs. buy-now).
- Our solution must allow selective enabling/disabling of certain filters by category — again, via config rather than code.
These points represent a 100% coverage of the filters and advanced scenarios typical in a robust discovery platform. They shaped our vision: build a scalable, future-proof architecture that could handle new filter types or dynamic behaviours by design — not by kludging them in later.
Structuring Elasticsearch Query Generation
We evaluated 3 approaches for building ES queries with aggregations:
Key-Value Pairs
{
"make": "Toyota",
"model": "Camry",
"fuelType": "Petrol"
}
✅ Simple frontend implementation
❌ Complex for hierarchical filters & fuzzy matching
❌ Too many flattened pairs
Frontend Lucene Queries [Selected]
OR
├── AND
│ ├── BOOST
│ │ └── FIELD: make = Toyota^2
│ ├── AND
│ │ ├── OR
│ │ │ ├── FUZZY: model = Camry~2
│ │ │ └── AND
│ │ │ ├── WILDCARD: model = Corolla*
│ │ │ └── REGEX: features = /.*safety.*/
│ │ └── NOT
│ │ └── OR
│ │ ├── RANGE (exclusive): year = {2015 TO 2020}
│ │ └── FIELD: color = Red
│ └── PHRASE: title = "Best Cars"~5
├── RANGE (inclusive): mileage = [5000 TO 10000]
├── AND
│ ├── FIELD: make = Honda
│ └── OR
│ ├── FIELD: model = Civic
│ └── AND
│ ├── RANGE (inclusive): year = [2018 TO *]
│ └── FUZZY: color = Blue~1
├── PHRASE: description = "luxury sedan"
├── EXISTS: reviewCount
└── AND
├── RANGE (inclusive): rating = [4 TO *]
├── PROHIBITED
│ └── RANGE (inclusive): price = [* TO 5000]
└── WILDCARD: field = *
✅ Compact, easy to save/share
✅ Supports advanced features (fuzzy, wildcards)
✅ Direct ES compatibility
❌ Frontend needs Lucene query building logic
Frontend ES DSL
{
"bool": {
"must": [
{ "term": { "make": "Toyota" } }
]
}
}
✅ Raw ES power
❌ Bulky for storage
❌ Security risk with complex JSON parsing
We chose Lucene queries for their balance of power and simplicity, plus excellent storage characteristics.
Our New Filter Architecture
1. Config-Driven Approach
A config-driven approach underpins our new filter architecture. Instead of hardcoding filters in multiple code files, we store all filter definitions (along with aggregator logic) in JSON. This makes adding or updating filters as simple as editing or injecting new JSON objects.
Below is a real-world example: Price Range slider.
Example A: Price Range Slider
{
"name": "PRICE_RANGE",
"category": "PRICE_RANGE",
"title": "Price Range",
"viewType": "SLIDER",
"order": 3,
"operators": ["OR"],
"options": [
{
"display": "Price Range",
"filter": {
"key": "price",
"value": {
"from": 10000,
"to": 5000000,
"stepRate": 5000
},
"queryTemplate": "price:[$value1 TO $value2]"
},
"count": "37",
"meta": {
"isSelected": false,
"selectedRange": null,
"formatType": "NUMBER",
"isSearchable": false,
"nuggetText": "\"₹\" + ((int)(selectedRange.get(\"from\")/1000)) + \"K\" + \" - \" + \"₹\" + ((int)(selectedRange.get(\"to\")/1000))+ \"K\"",
"prefix": "₹",
"postfix": "",
"minLabel": "Minimum",
"maxLabel": "Maximum"
}
}
],
"meta": {
"isSearchable": false,
"heading": "Select Price"
}
}
- viewType: "SLIDER" indicates a UI slider for selecting a price range.
- queryTemplate: "price:[$value1 TO $value2]" tells the frontend how to build a Lucene range query for the chosen “from” and “to” values. Each query template is designed as per viewType and the client understand how to fill queryTemplate.
- nuggetText: An MVEL expression that transforms the numeric range into a readable string (₹10K - ₹500K, for example).
When the user slides from \₹10,000 to \₹5,00,000, the frontend plugs those values into the query template — producing something like:
price:[10000 TO 50000]
Why Config-Driven?
- Centralized Logic
- All filter rules live in a single JSON “source of truth,” reducing fragmentation across codebases.
- Flexible Query Templates
- The queryTemplate handles advanced Lucene features (ranges, fuzziness, booleans) without complex code rewrites. This is one time development for each viewType as the handling might change for each.
- Simple Updates
- Adding or modifying filters — like “Battery Capacity” for EVs — just requires inserting a new JSON block with the correct queryTemplate.
- UI/UX Control
- The meta field governs display elements (labels, placeholders, search hints), enabling quick changes without fresh deployments or code merges.
2. Lucene as the “One Language”
Whenever a user picks “Petrol,” “Diesel,” or “CNG,” we convert those selections into a Lucene string like (fuelType:Petrol OR fuelType:Diesel OR fuelType:CNG). We send one query string to the backend, which passes it to Elasticsearch for both search and aggregations.
3. Dynamic Facets & Aggregations
Using Elasticsearch aggregations, we retrieve counts for each filter option in real time. For instance, if the user selects Audi, we run a “terms” aggregation for modelId and get updated counts for A3, A4, A6, etc. This powers a dynamic, facet-driven UI.
3. AST-Based Uniqueness for Saved Filters

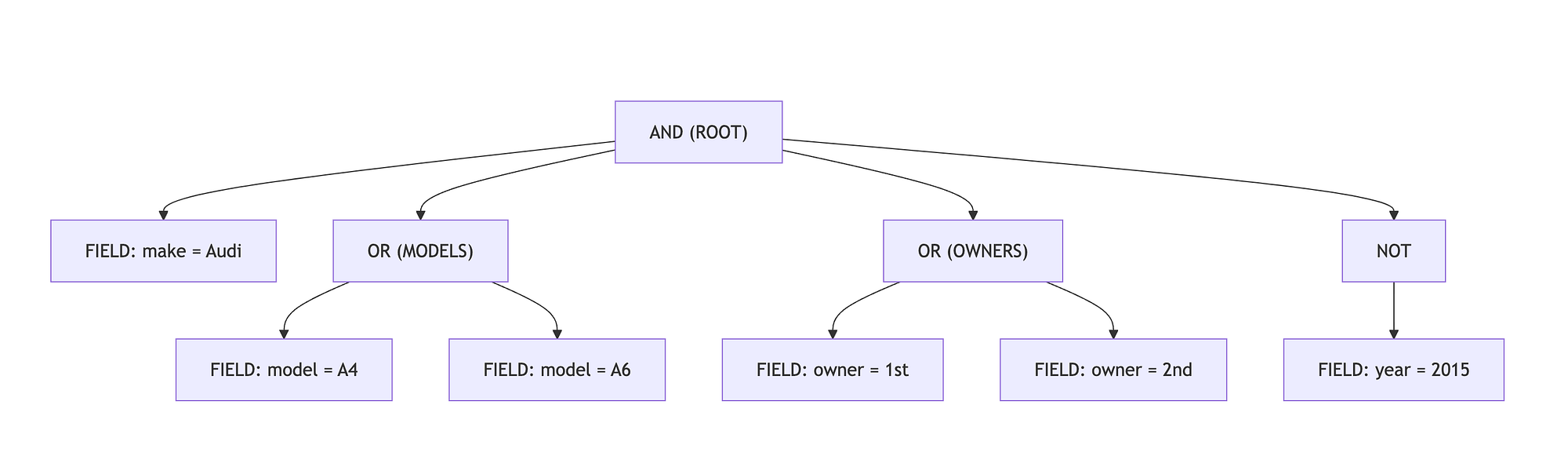
When a user selects (Make: Audi AND Model: A4), it’s logically the same as (Model: A4 AND Make: Audi)—but if we naively store these sequences, we’d end up with two saved filters that do the same thing. By constructing an Abstract Syntax Tree (AST), sorting the nodes at each level, and then flattening them into a canonical form, we ensure the same filter always produces the same representation, regardless of the order in which filters were chosen.
Example: A More Complex Filter
Suppose a user picks:
- Make: Audi
- Model: A4 OR Model: A6
- Owner: (1st Owner OR 2nd Owner)
- NOT (Year: 2015)
In one session, they might select “Make → Model → Owner → Exclude Year” while in another, they do “Exclude Year → Model → Make → Owner.” Ultimately, we want the same tree (and thus the same hash).
Below is a Tree showing how such a filter might look internally as an AST once we standardize the order of operations:
5. Supporting Special Use Cases
Carousels, banners, or custom CTAs often need specialized filters — think “Scrap Cars,” “Auction Ending Soon,” or even “Premium Cars Under 5L.” Once your system speaks Lucene, these scenarios become trivial. For Example:
Below is a mockup showing how easy it is to offer multiple fuel filters — Petrol, Diesel, CNG — powered by the new architecture:
- Tapping Petrol yields fuelType:Petrol.
- Tapping Diesel becomes (fuelType:Petrol OR fuelType:Diesel) or fuelType:Diesel (Whatever way we want the behaviour of the product)
The beauty is that any CTA on your site can embed a Lucene query. Imagine a homepage with curated carousels:
- “Petrol under 2,50,000” → (fuelType:Petrol AND price:[* TO 250000])
- “Premium Cars on a Budget” → (premium:true AND price:[* TO 500000])
When the user clicks, they see only the relevant filtered listings — no extra logic or code branching is needed. Everything is “just a filter” in Lucene. This not only centralizes how you manage these special categories but also makes it incredibly easy to add new ones tomorrow. You’re simply binding a CTA to a stored query string — no new feature flags, no new endpoints, just a neat, single-language solution that fits elegantly into your existing filter architecture.
Technology Stack
A broad range of libraries, frameworks, and tools enable this robust filter system:
Java Libraries
- JsonPath: Reads values from JSON configs (like the count field or aggregator paths) using simple path expressions ($.options[0].filter.queryTemplate).
- MVEL Expression: Used to evaluate dynamic expressions for fields like nuggetText, enabling runtime calculations (e.g., range = "₹" + (from/1000) + "K").
- Regular Expressions: Employed to match certain patterns in queryTemplate or to detect isSelected flags in the user’s Lucene query.
- Jackson Databind (JSONNode): Deserializes JSON configs into tree structures, allowing easy recursive traversal and updates.
- Apache Lucene: Powers the internal representation of queries before sending them to Elasticsearch for certain specialized pages (previously using raw Elasticsearch DSL).
Caching & Storage
- Caffeine: Caches system filters and facet configs in memory. This ensures faster lookups once the config is loaded from the database.
- MongoDB: Acts as the central source of truth for all filter configs.
- Redis PubSub: Synchronizes updates to filter configs across multiple running pods. When a config changes, a PubSub message triggers an immediate cache refresh.
Tools for Backend
- Elasticsearch: The search engine that fetches car data and runs aggregations for facets.
- Redis PubSub: (Repeated here for clarity) used for cross-pod communication whenever config changes.
By layering these technologies, we get a powerful yet configurable filter system. Any new filter or aggregator is essentially a new JSON entry, letting teams iterate quickly on product requirements without the overhead of extensive code changes. This synergy of JSON-based configs, Lucene queries, and dynamic Java libraries forms the backbone of our next-generation filter experience.
Conclusion
Re-architecting our filter system at Cars24 wasn’t just about handling bigger data volumes or adding a few extra knobs — it was about reimagining how search and discovery can empower channel partners to find the perfect car. From introducing a config-driven approach to adopting Lucene Query Syntax for advanced filtering, our new system is both flexible and future-proof.
Behind every innovation is a dedicated team. A special shout-out goes to:
- Aditya Choudhary — Who worked tirelessly, ensuring we never compromised on any feature while driving backward from vision.
- Aniket Gupta — The frontend hero, who championed the interface and query generation logic.
- Kushendra Suryavanshi — Our rockstar Product Manager, expertly orchestrating requirements.
- Akshay, Vikas, Prateek and Ayaz — For adding those crucial finishing touches to the entire process.
- Kritika and Bhavika from Design — Who brought aesthetic consistency and a seamless user experience to the table.
Together, this collaboration has set the foundation for a robust, scalable, and configurable filter experience — one that will continue evolving with future business needs and customer expectations. We hope our journey inspires you to think bigger about how you handle filtering, aggregations, and search architecture in your own projects.
Loved this article?
Hit the like button
Share this article
Spread the knowledge
More from the world of Cars24
Building Resilient Node.js BFFs at Scale: Hard-Earned Lessons from Production
The difference between a BFF that handles 100rps and one that handles 10,000rps isn’t some magical framework.
When Voice AI Loses Track of Reality
I hope my findings shared here make a meaningful contribution and have a positive impact on how voice AI systems are designed and evaluated.
From Feedback to Visible Change: A Gentle Rhythm for Team Observability
Leaders spend less time firefighting and more time enabling, because patterns in the trend point to structural fixes.