Cracking OCR at Scale: Lessons from Real-World Document Processing
At Cars24, where speed and scale go hand in hand, automation isn’t just a luxury — it’s a necessity. Powering this efficiency behind the scenes is our in-house Document Processing system, built to transform messy, unstructured documents into clean, structured insights.
From RCs and insurance papers to ID cards and number plates, the OCR system pulls out essential details from all kinds of documents. While it’s built on the robust PaddleOCR framework, we’ve fully self-hosted and customized it to align with our unique workflows and performance needs.

OCR Automation
In this blog, we’ll dive into the inner workings of our Document Processing system — how it’s architected, the challenges we encountered and overcame, and the tangible impact it continues to have on our daily operations.
Why We Chose PaddleOCR
When choosing an OCR solution for large-scale document processing, we needed something accurate, modular, and easy to tailor to our use cases. After trying several options, PaddleOCR stood out as the most balanced and production-ready framework.
It offers an end-to-end OCR pipeline with strong performance in detection, classification, and recognition. But what truly made it work for us was its flexibility. We could adapt and extend it based on our business needs.
This level of control without being tied to a rigid setup made PaddleOCR the ideal fit for our evolving OCR needs.
What We Didn’t See Coming: Real-World OCR is Never One-Size-Fits-All
When we first evaluated PaddleOCR, it checked all the right boxes — modular design, multilingual support, and impressive out of the box accuracy. It looked like a plug and play solution to power our document understanding needs at Cars24.
But as we began integrating it into real workflows — parsing insurance documents, RC books, plastic cards, and license plates in real time we quickly discovered that production-grade OCR at scale is a different beast entirely.
Problem: One OCR Pipeline, Many Use Cases
Our OCR system wasn’t just solving one problem — it was solving many, all at once.
The types of documents we needed to process varied significantly:
- RC (Registration Certificate) documents — relatively simple, short, and structured.
- Insurance papers — long, dense, often messy, with small font sizes and tabular layouts.
- Images of vehicles — where the goal is to quickly extract the registration number from a license plate.
- Already cropped word boxes — provided by internal tools or upstream models, where detection isn’t needed at all.
Multitasking? More like multi-mess.
Each of these came with different complexity in delivering higher accuracy solutions:
- RC documents can get faded with hard to detect text
- Insurance documents contain small text — where single image contain whole A4 sheet paper
- Number plate of cars have varied font ( The lack of a nationwide mandate for High Security Number (HSN) plates has led to widespread use of non-standard, hard-to-read fonts on vehicle plates.)
- Chassis number embossing — this is eangraved text and not written so pattern is completely different
- And some needed the flexibility to skip steps entirely (like skipping detection when cropped inputs are available).
PaddleOCR gave us a strong foundation, but it assumed a linear flow: detect → classify → recognize.
That wasn’t going to cut it across this diverse landscape.
No single OCR pipeline however modular could balance accuracy, speed, and adaptability across all these cases. We needed a smarter way to route different documents through different paths, depending on the context.
In between, we also hit other practical challenges:
- Tiny text that standard detectors would miss
- Low-resolution uploads, WhatsApp-compressed images, and poor lighting
- Confusion between similar characters like ‘O’ and ‘0’, ‘I’ and ‘l’
No single OCR pipeline — however modular — could balance accuracy, speed, and flexibility across all these scenarios.
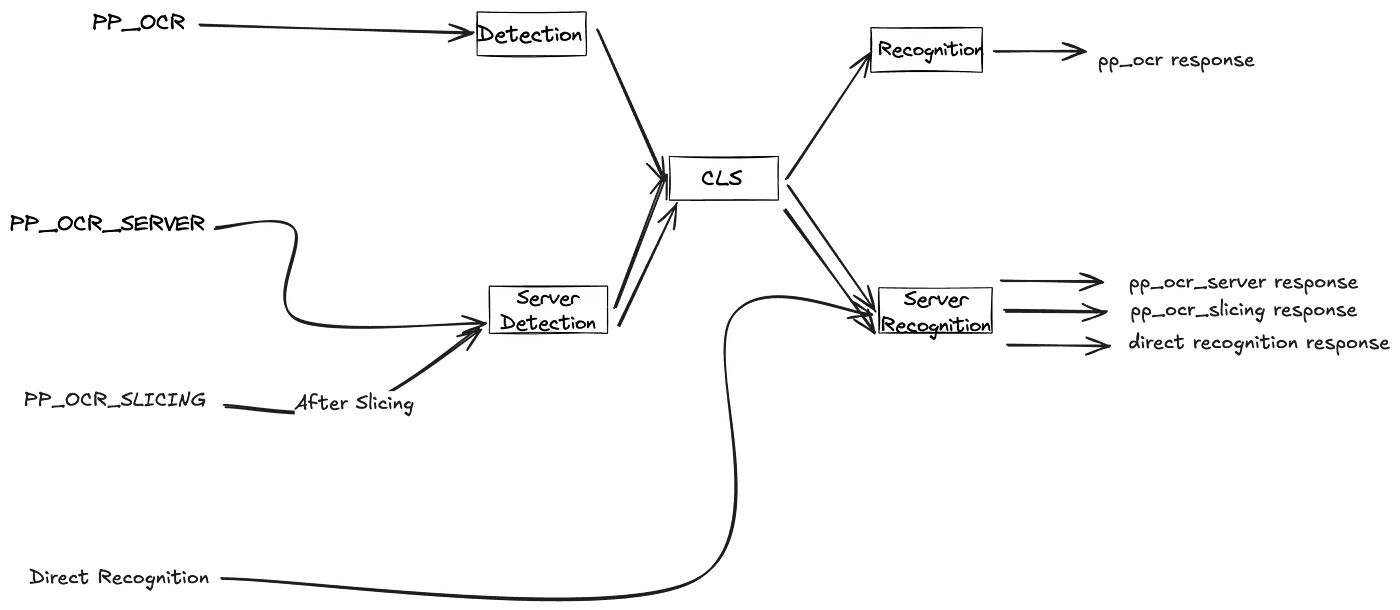
Our Solution: Multi-Model, Auto-Routed OCR Deployment
To address this, we built a multi-path OCR architecture using the NVIDIA Triton Inference Server — one that intelligently routes each request to the right pipeline based on the use case.
🔁 The Three Core Pipelines
1. pp_ocr — Lightweight General-Purpose Pipeline
Designed for simpler documents and faster processing. It uses:
- Lightweight detection and recognition models
- Shared sub-ensembles for classification (cls_pp) and recognition (rec_pp)
- Best suited for basic documents with predictable layouts
2. pp_ocr_server — Heavyweight Pipeline for Complex Documents
This mirrors the pp_ocr structure but swaps in:
- Heavier models (det_runtime_server, rec_runtime_server)
- Larger backbones for better accuracy on messy or dense documents
- Still reuses the lightweight classification ensemble
3. pp_ocr_slicing — Specialized for Small, Dense Text
For hard-to-detect tiny fields, this pipeline:
- Slices the image into smaller overlapping tiles (det_preprocess_slicing)
- Batches them through the server-grade detector
- Merges and reconciles results, then runs classification and recognition
This slicing-based approach helped us go from 70% to over 90% accuracy in extracting entities from densely packed insurance and RC documents.

Direct-to-Recognition Pathway
Some of our internal systems already supply cropped word boxes, such as:
- Number plates detected by external logic
- Specific ID fields in structured forms
For these, we skip detection and classification, and directly route the box to the recognition pipeline (rec_pp or rec_pp_server).
This significantly improves latency and throughput without compromising accuracy.
Why Triton and Ensembles?
Using Triton Inference Server allows us to:
- Chain multiple models (preprocess → detect → classify → recognize) into a single inference pass
- Dynamically route documents to the most appropriate pipeline
- Reuse common components like cls_pp across pipelines
- Independently update detection or recognition models without touching the rest
- Scale reliably with GPU-aware request scheduling and multiple model instances
Solving the use-case diversity problem wasn’t about building one perfect pipeline — it was about building a flexible system of pipelines, each optimised for a specific type of document or scenario.
And with Triton and PaddleOCR as our foundation, we were able to do just that.
The Roadblocks: Latency and Memory Spikes in Production 🚧
Latency Bottlenecks
Inference time per image: 1–1.5 seconds — acceptable in isolation but unsustainable under high concurrency (batch jobs, bursty workloads). Resulted in queue build-up, delayed responses, and timeouts and service having a scalability blocker.
Random GPU Memory Spikes
Triton’s GPU memory usage would surge unexpectedly without changes in batch size or request complexity which caused memory creep leading to server to have out of memory crashes. Due to the unpredictability of this issue it was difficult to reproduce but critical due to production uptime demands.
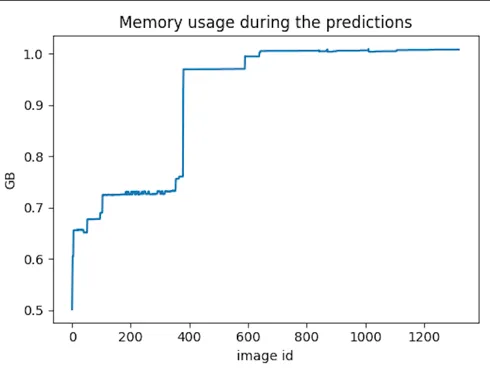
Memory:’I can take it, I can take it.’ — dies quietly at the top 🪦.
Digging Deeper: Why the Memory Kept Spiking
Root Cause: Frozen GPU Memory & Oversized Inputs
- ONNX inference framework dynamically allocated GPU memory based on input size but never released or scaled it down.
- This wasn’t an issue with uniform input sizes, but our pipeline saw wide variance:
- High-resolution document images spiked detector memory usage.
- Long word boxes (e.g., an entire text line treated as one) inflated recognizer input size.
- Result: Memory stayed “frozen” at peak usage, causing gradual GPU memory creep until crashes.
Flawed Merging Logic Compounded the Problem
- PaddleOCR’s default slicing merge logic assumed axis-aligned boxes.
- On skewed/angled documents, it produced distorted merged boxes with extreme aspect ratios. Resizing these for the recognizer led to large, irregular input vectors:
- Triggered abrupt GPU memory jumps.
- Increased inference time, adding to latency and queue build-up.
Path to Stabilization
- Enforce input size limits to block oversized requests.
- Refactor merging logic to handle non-axis-aligned word boxes gracefully.
- Optimize model behavior for variable input sizes to prevent GPU overuse.
How We Solved It: Smarter Input Control & TensorRT Optimization
To tackle both the memory instability and inference latency challenges, we introduced a combination of input size control and model optimization using TensorRT.
1. Setting Input Size Limits
We analyzed the distribution of input shapes — both document dimensions and word box lengths and identified optimal size thresholds that:
- Avoided overburdening the GPU
- Preserved model accuracy
- Prevented oversized requests from slipping through
By putting bounds on the input sizes, we were able to stabilize GPU memory usage and also reduce inference time.
2. Converting ONNX to TensorRT
We also replaced our ONNX models with TensorRT-optimized versions of the detector and recognizer.
TensorRT provided two major benefits:
- Speed: The TensorRT models delivered noticeably faster inference compared to their ONNX counterparts.
- Memory Predictability: During conversion, we explicitly set the minimum, optimal, and maximum input shapes expected for each model. This meant TensorRT could pre-allocate memory efficiently for this range, avoiding the dynamic allocation behavior that ONNX suffered from.
The Outcome 🎯
With these changes in place, we saw significant improvements:
- Inference time was reduced, allowing us to handle higher request volumes without queue build-up.
- GPU memory usage stabilized, eliminating the unpredictable crashes we previously faced.
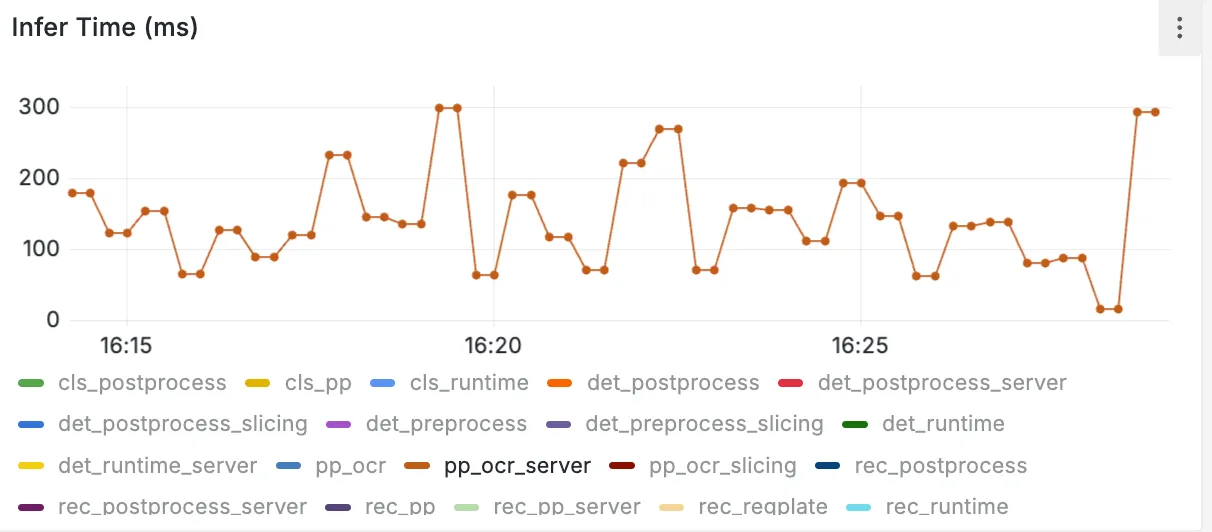
The inference time got down to under 500ms increasing the throughput of the model💃🎉
Looking Ahead: From OCR Pipelines to Vision-Language Intelligence
While our current OCR system — built on detection, classification, and recognition — has come a long way in performance and scalability, we’re already looking ahead.
The future of document understanding moves beyond stepwise pipelines. Instead of separate models for detection, orientation, and recognition, we’re transitioning to a unified architecture: Vision-Language Models (VLMs).
VLMs don’t just extract text — they understand context. By combining visual layout with language understanding, they can directly answer questions like:
- “What is the registration number?”
- “Who is the insured person?”
- “When does the policy expire?”
All without manual detection or cropping.
This marks a fundamental shift in OCR. VLMs interpret structure and semantics much like a human would, enabling them to:
- Extract specific entities from prompts
- Resolve ambiguities (like ‘O’ vs. ‘0’)
- Generalize across formats without retraining
At Cars24, we’re actively fine-tuning VLMs for our documents — from RCs to insurance forms. Early results show gains in both accuracy and inference speed.
The goal? To move beyond OCR toward true document intelligence, where systems understand rather than just read.
Conclusion: From Problem-Solving to Production-Grade OCR
Building a reliable OCR pipeline sounds simple — run models, extract text, done. But at production scale, across diverse documents like insurance papers, ID cards, and license plates, the reality is far more complex. We faced challenges with inconsistent formats, character ambiguities, latency, and GPU memory spikes. While PaddleOCR offered a solid base, it required deep customization and infrastructure-level engineering to meet production demands. By adopting a modular Triton architecture, enforcing input controls, and optimizing models with TensorRT, we built a system that is scalable, stable, and adaptive — processing everything from full documents to word crops with speed and reliability. Ultimately, this journey reinforced that real-world ML isn’t just about model accuracy — it’s about engineering, experimentation, and iteration.
Loved this article?
Hit the like button
Share this article
Spread the knowledge
More from the world of Cars24
No Human in the Loop: Cars24's First AI Loan Workflow
What it takes to ship AI that owns a workflow end to end
How a non-engineer built the tool 1000+ people at Cars24 now use
Story of how an autonaut noticed a problem, brainstormed it with Claude, learned Cloudflare in three days & shipped a tool 1000+ people now use
Analytics should drive decisions, not describe them
How we stopped burning thirty hours a week on “what happened” and started using that time to decide the future