How Our Fine-Tuned Whisper is Revolutionising CARS24’s Call Intelligence
Introduction: The Invisible Listener in Every Customer Call
Conversations between a customer and Cars24 agent have different purposes, spanning from understanding the car, negotiating offers, understanding processes to maybe rescheduling an appointment. And at Cars24, from customer first perspective, we are interested in understanding -
- Was our agent able to answer the queries?
- Was agent patient enough to address the problem?
- What are the common areas of knowledge gap for internal training of agents?
- What should be the next steps to meet customer expectations?
To find the answers to these questions, there’s a silent observer working behind the scenes: an AI-powered listener transcribing and analyzing every word, extracting insights, identifying fraud, and even spotting missed sales opportunities.
Welcome to the world of Automatic Speech Recognition (ASR) at Cars24, where our fine-tuned Whisper model is reshaping how we process millions of customer calls.
💎 The Hidden Treasure in Cars24’s Calls
Every single day, hundreds of thousands of calls flow between Cars24 customers, agents, and dealers. These calls are rich with business-critical signals:
- ❗ Customer frustrations: “Why did my offer decrease?”
- 💰 Negotiations: “Thoda aur de do bhai, gadi achhi hai.”
- ⚠️ Fraud alerts: Fake buyer conversations or refund scams.
- 🧨 Lead leakage: “Call me on my personal number.”
- 💡 Feedback goldmine: Customer pain points & expectations.
- 😬 And sometimes… off-topic personal chitchats that have nothing to do with cars 😅
Before going live with this module, we were working in a reactive way, where only flagged conversations were checked manually. Yet, 99% of these calls would go unanalysed, simply because manually listening to them is impossible.
That’s exactly where ASR — and specifically our Whisper-powered engine — steps in.
🎯 The ASR Challenge: Decoding the Indian Call Landscape
India isn’t your typical ASR use case. Our calls are uniquely challenging, and off-the-shelf models like Google STT or AWS Transcribe just didn’t cut it.
Here’s why:
1️⃣ Multilingual Mayhem
- Calls often mix Hindi, English, Tamil, Telugu, and Kannada.
- Code-switching is natural: “Sir, RC transfer karwana hai. What’s the fee?”
- Regional accents and phonetic shifts make ASR harder.
2️⃣ Real-World Audio Chaos
- Honking cars, background chatter, low-quality mics.
- Overlapping speakers and call-center noise.
3️⃣ Domain-Specific Jargon
- Cars24 lingo: RC Transfer, Loan NOC, Scrap value, Car models name, regional address.
- Generic ASR models struggle with these terms.
We needed something custom, something smarter, and definitely something built for Cars24.
💪 Motivation of This Work: Why We Had No Choice but to Build Our Own ASR
Let’s be blunt: India’s call landscape breaks traditional ASR systems.
Most global ASR tools — be it Google STT, AWS Transcribe, or even Whisper out-of-the-box — are built for clean audio, fluent and clear accents. That’s not India.
Cars24 operates across India, UAE, and Australia, and while 95%+ of calls in UAE and AUS are in English (handled well by out of the shelf Whisper), India is a whole different beast.
Here’s what we’re dealing with in Cars24 India:
- Hindi dominates 50% of the volume with a mix of english.
- The remaining 50%? A chaotic mix of Tamil, Telugu, Kannada, Punjabi, Marathi, and more.
- Within that “other” 50%, Tamil, Telugu, and Kannada make up to 90% — they’re the toughest languages for ASR models today.
Just to clarify — every regional language we dealt with had some English mixed in, sometimes just a bit, and other times over 50% of the conversation.
🔎 We Tested Off-the-Shelf Models — And They Crumbled
We ran these models across our real-world, multilingual call data. The results were underwhelming at best.
Here’s what went wrong:
- Hallucinations — Invented words and repeated phrases showed up way too often.
- Cars24 Lingo? Nope. — They couldn’t grasp our domain-specific terminology.
- Code-Switching Chaos — Switching between Hindi, Tamil, or Kannada with English thrown in? They just couldn’t keep up.
“Bottom line? These models weren’t designed for the kind of linguistic diversity found in India, or the messy, real-world audio we encounter every day. So, we had to build our own.”
We needed real-time, high-accuracy transcription at scale. For millions of calls, across dozens of accents, with domain-specific fluency.
So we did what any engineering-first company would do — We took matters into our own hands.
We started with Hindi — the largest chunk of our Indian call volume.
Then we scaled our approach to tackle Tamil, Telugu, and Kannada — bringing 90% of Cars24’s Indian calls under high-fidelity ASR coverage.
🛠️ How We Fine-Tuned Whisper
We built this a year ago, when we started, out-of-the-box models struggled — especially with Cars24-specific language. Words like “Cars24”, car models, and phrases like “Sir 50 extra kra dege, isse zyada nahi ho payega” often get misinterpreted. Context was missing. Accuracy was off.
We knew fine-tuning was the only way.
🚧 The Data Collection Grind
We followed weak supervision techniques, inspired by Whisper’s own training approach:
- Scraped data from Internet, similar approach mentioned in the whisper paper ( look at the 2.1 section of the this paper)
- Collected open source data like AI4Bharat, CommonVoice, fleurs etc.
- Additionally exploit LLMs for Data Preprocessing
- Applied multiple custom heuristics/stages to filter noisy data.
But it wasn’t easy.
📊 Dataset: 50 hours ❌ Failed
📊 Dataset: 100 hours ❌ Failed again
📊 Dataset: 150 hours ❌ Still no improvement
📊 Dataset: 500 hours ✅ Slight improvement, but not enough
We realised the model was overfitting on generic data and failing on out of distribution data.
To deep dive at the problems we are facing you can check the hugging face forum where we have highlighted the issues:
- https://huggingface.co/spaces/openai/whisper/discussions/107
- https://huggingface.co/spaces/openai/whisper/discussions/100
We tried multiple variants of whisper(whisper small, whisper medium, large v2 etc.)
🔍 The Breakthrough: Proprietary In-House Data
To build something truly reliable, we knew generic datasets just wouldn’t cut it. So, we looped in our product team and scaled — aggressively.
- We built an in-house annotation team from scratch.
- We sampled hundreds of hours of real Cars24 call data to reflect genuine customer-agent interactions.
- Since Whisper can only process audio chunks of up to 30 seconds, we randomly segmented calls into 0–30s slices and transcribed them in English. (Yes, choosing English was intentional — we’ll get into why soon.)
Annotation for Hindi? Pretty straightforward — it was easy to find people fluent in both the language and the business context.
But the real uphill battle? Regional languages.
As a developer, I couldn’t validate if what annotators wrote was correct — I simply didn’t understand the language well enough. That’s when we made a bold move and turned to our regional teams.
Thanks to support from Business and Product, We turned to our biggest hidden asset: we started using our own call Center team for annotations.Who better to annotate Tamil, Telugu & Kannada than the very people who handle those conversations every single day?
We tapped into that goldmine — and it paid off big.
🛠️ Annotation Tooling
To enable this at scale, we built a lightweight yet powerful Streamlit app hosted on our GKE cluster.
The tool was designed to handle over 100 concurrent users seamlessly.
Annotators could:
- Listen to the audio
- Transcribe it simultaneously
- Select the spoken language
- Flag audio quality
- And compare their transcriptions with off-the-shelf model outputs — all in one smooth interface.
Later, this tool was also repurposed to validate transcriptions, making it an integral part of our quality assurance pipeline.
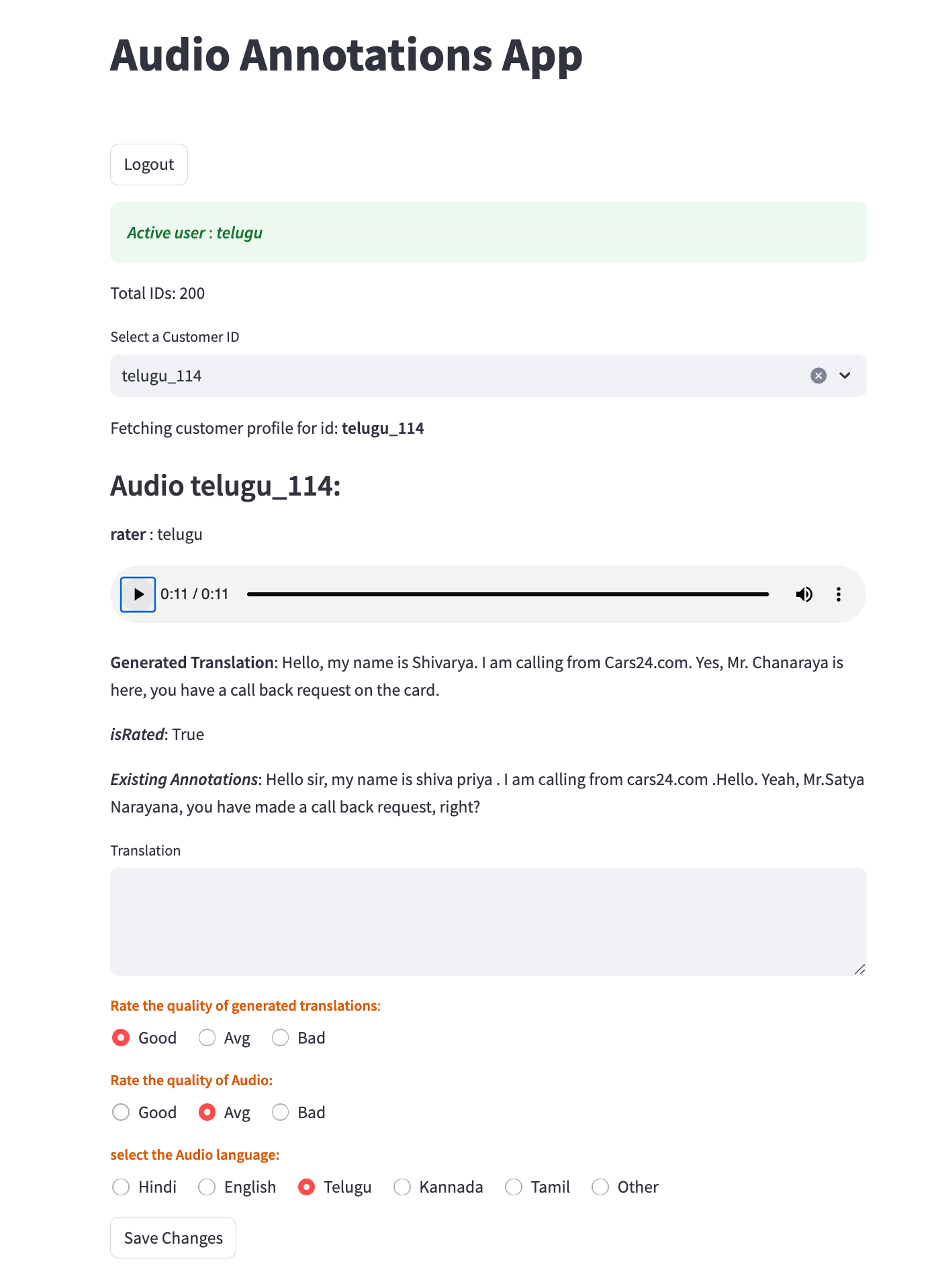
Let’s be honest — this process wasn’t quick. Transcribing a 30-second chunk took an annotator around 2–3 minutes on average. Hearing and typing in real-time is mentally taxing — and we made peace with the grind, because quality matters.
🔢Training stats
To better understand the performance and reliability of our finetuned model, we compiled key insights from the training pipeline. This includes information about the dataset, audio duration patterns, and a series of visualisations that highlight the overall data quality and balance. Additionally, we provide details on the training environment and hyperparameters that contributed to efficient and effective learning.
The model was trained on an NVIDIA L4 GPU using mixed-precision (fp16) training, which significantly accelerated the optimization process while reducing memory usage. Below, we break down the dataset characteristics, training setup, and the major modifications that enabled streamlined and scalable training.
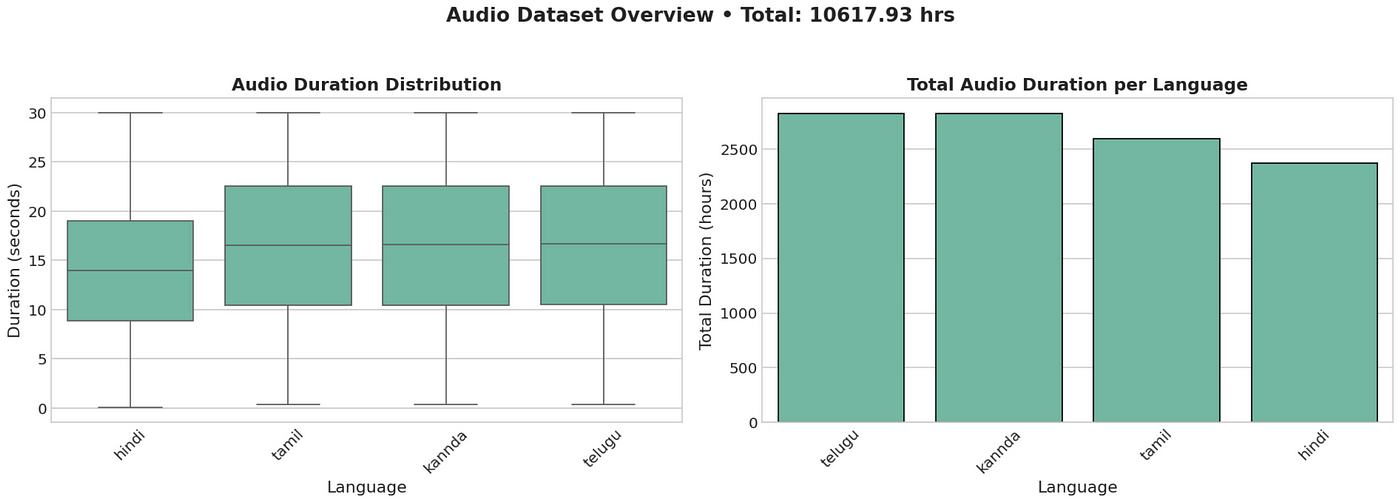
Finetuning data distribution
We began with the Whisper fine tuning notebook as our base, and then tailored it extensively to better suit our use case. Key enhancements include:
🚀 Optimised data pipeline with optimized data_collator and prepare_dataset functions
🌐 Dynamic tokenizer that injects the appropriate language token at runtime
📦 Streamable dataset loading for improved efficiency and scalability
🧵 Parallelised preprocessing: Data was prepared on-the-fly using multiple workers, with seamless streaming from our GCS bucket for maximum efficiency.
Hyper-parameters and training logs
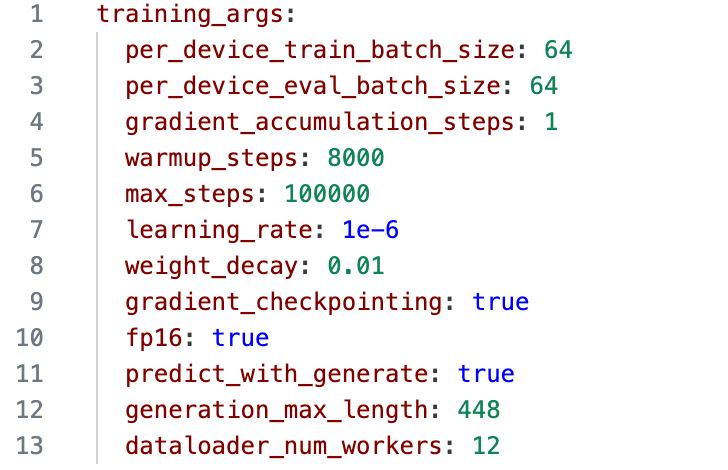
Hyperparameters
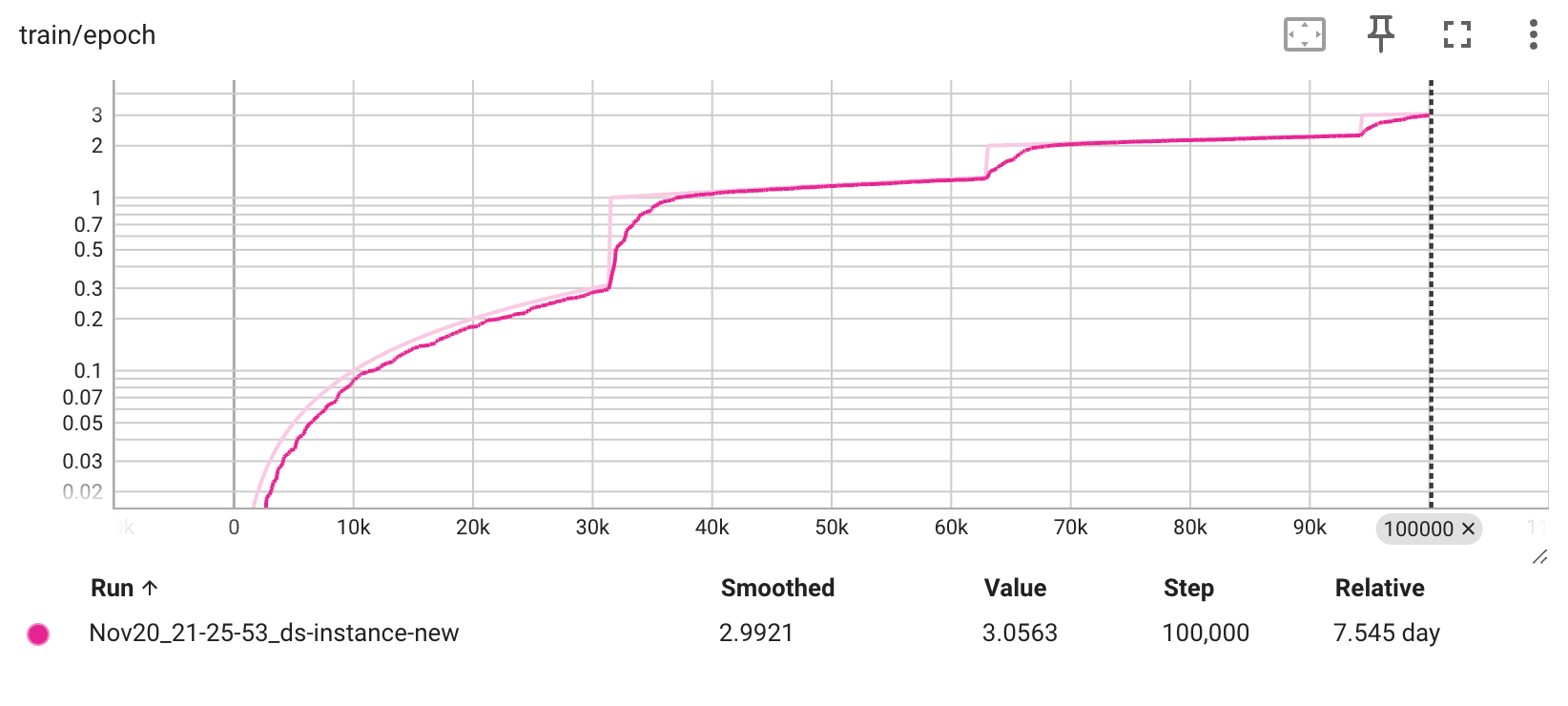
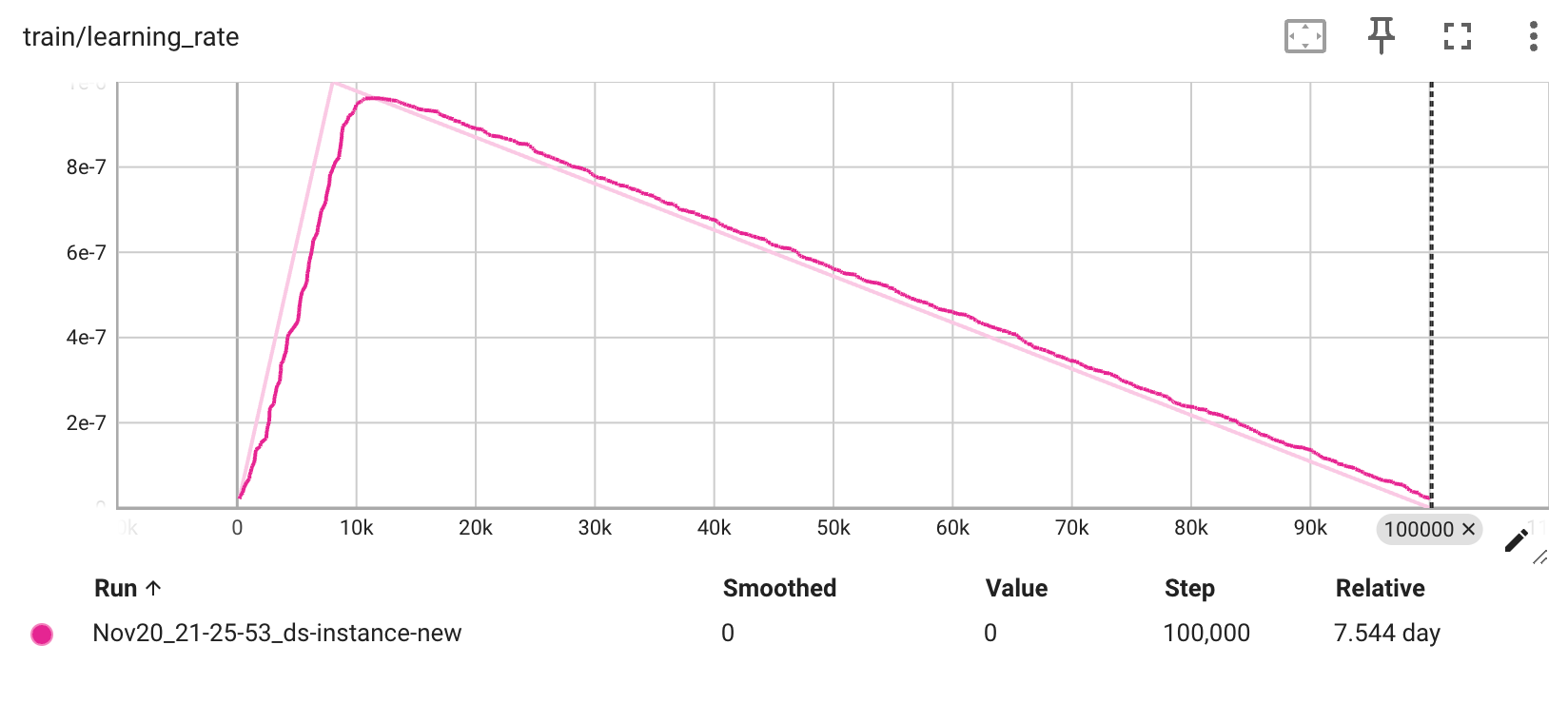
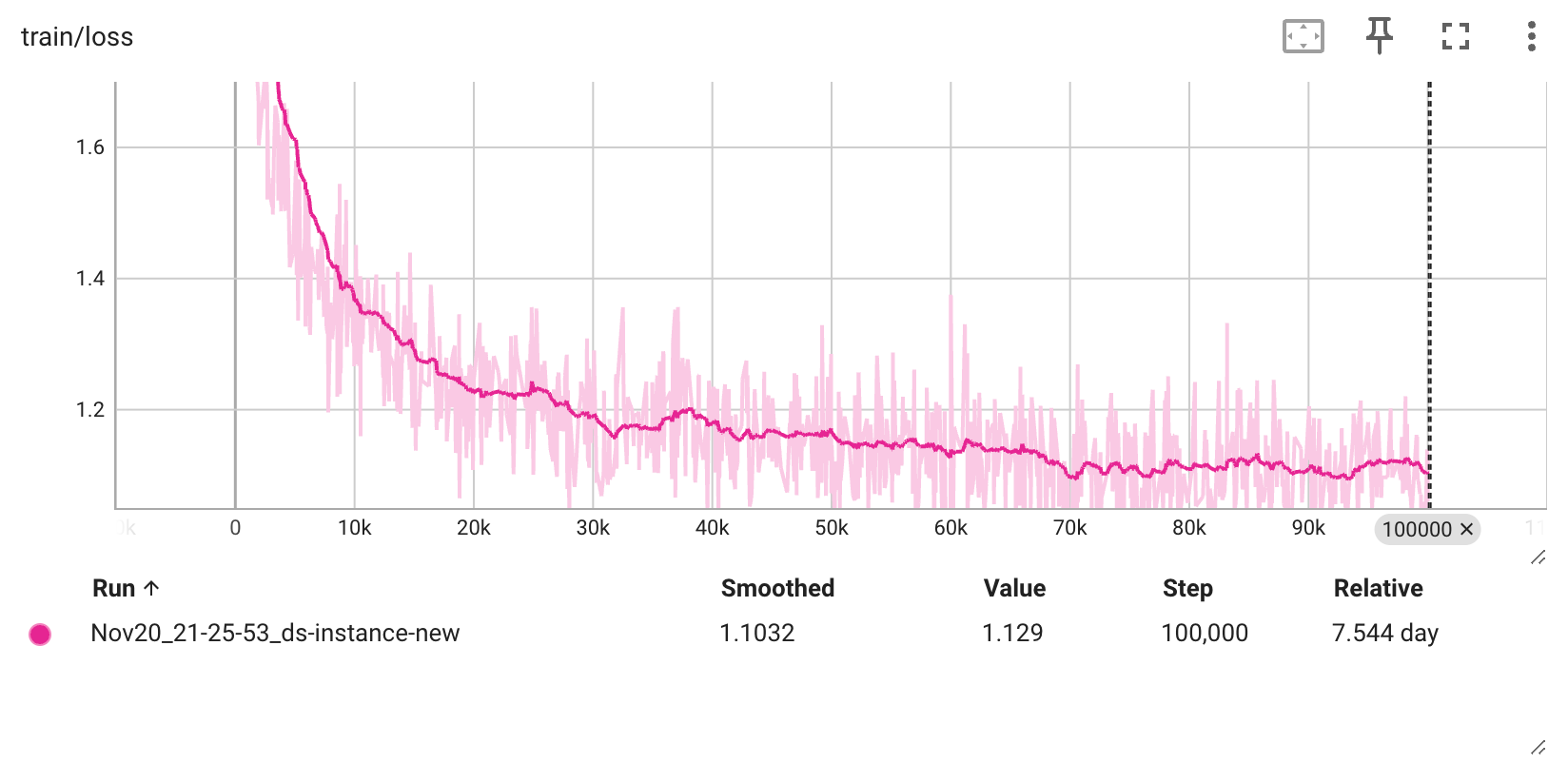
Training logs
We’ll dive deeper into the training process in a follow-up article — covering experiments, optimizations, and lessons learned along the way. Stay tuned!
🎯 Bullseye:: The Result
A dramatically more accurate, robust Whisper variant — engineered specifically for multilingual, real-world conversations.
We call it: SPEECH-24
🔁 Why We Chose Whisper’s Translation Mode Over Transcription
Here’s a cool twist — we use Whisper’s translation mode instead of transcription.
Why? 🤔
🧠 More Training Data for Translation
Whisper’s training dataset is richer for translation than transcription for Indian languages.
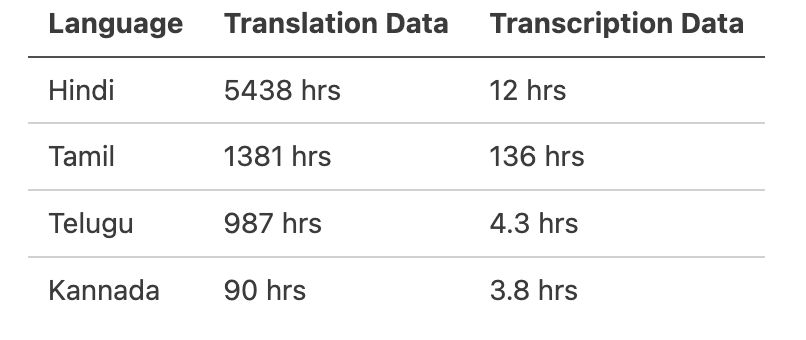
Training Dataset Statistics from whisper paper
🧬 Better Token Efficiency
Whisper used gpt2- tokenizer, which is not optimized for regional languages. Our thought process
- English requires fewer tokens than native scripts.
- “Hey, buddy, how are you?” → 8 tokens
- “अरे दोस्त, तुम कैसे हो?” → 23 tokens
- Fewer tokens = Better throughput.
🌀 Multilingual Mixing
- Calls often mix languages in a single sentence: “Hi sir, I am calling from Cars24. आपसे इंस्पेक्शन के लिए बात करनी थी।”
- Translation mode elegantly converts mixed-language content into coherent English.
🤖 Beyond Transcription: LLMs That Extract Business Gold
Transcription is just step one. We built custom LLM-powered wrappers on top of transcription output to:
- 🧠 Extract Events: e.g. “Customer agreed to sell.”
- 🛑 Detect Fraud: e.g. Fake refund requests or agent misuse.
- 🧩 Summarize Conversations: e.g. “Customer is frustrated due to delayed payment.”
We convert speech → text → structured insights, providing Cars24 a 360° view of customer interactions.
📊 Benchmarking: Speech-24 vs The World
We benchmarked Speech-24 against major ASR services using:
- 🔁 Cosine similarity
- 🔤 BLEU scores
- ✅ Human validation (91% correlation on Hindi, ~89% on Tamil/Telugu/Kannada)
our benchmarking scores is based on the human and cosine similarity correlation metric.
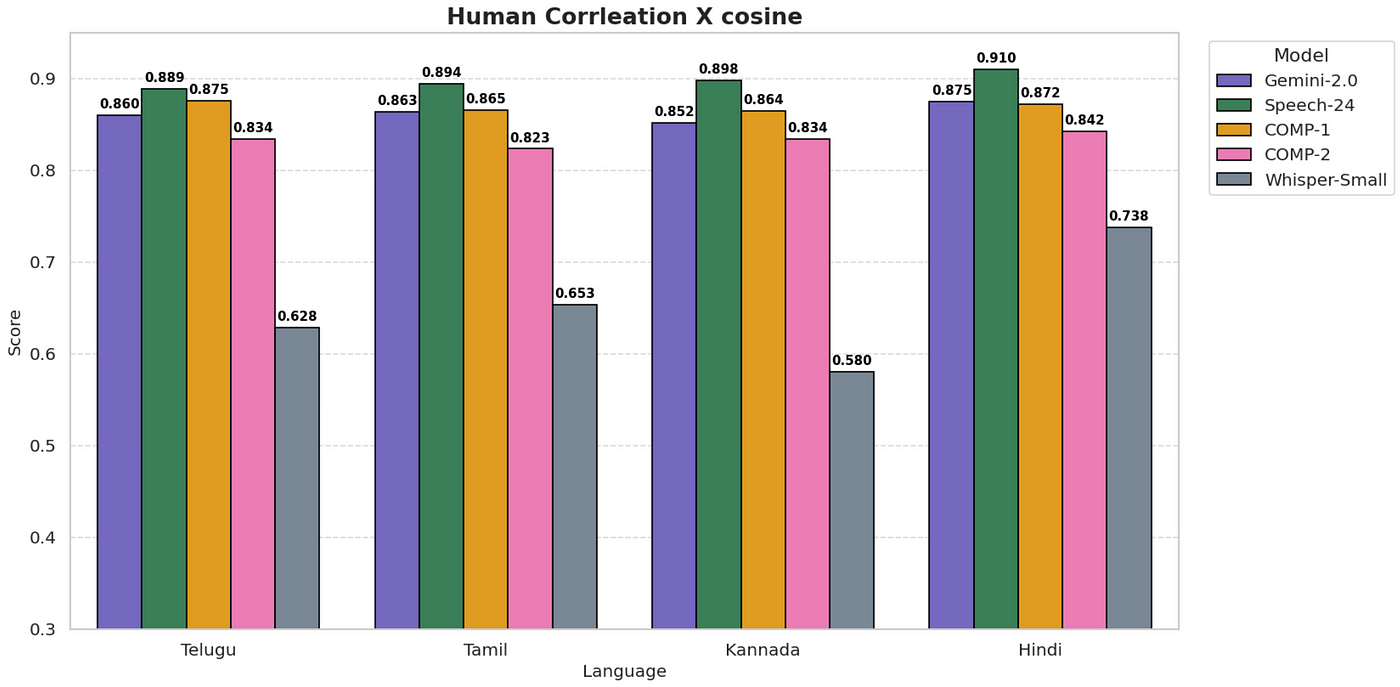
Benchmarks scores
Note: COMP-1, COMP-2 are the third party vendors, offer similar service with heavy pricing.
On real-world Cars24 call data, Speech-24 outperformed commercial ASRs — both in accuracy and relevance.
⚙️ Infra Efficiency — Built for Scale
- 🔁 RTF (Real-Time Factor): Blazing fast — ~100x on a single NVIDIA T4.
- 📦 Scalable Throughput: Capable of processing 2,000+ hours of audio per day, without breaking a sweat.
- 🧠 Multiple Whisper Variants: We’ve deployed not one, but three finely-tuned Whisper models on a single T4 GPU (we will publish a detailed article covering about deployment strategy).
💰 Cost Efficiency? Unmatched.
Our end-to-end transcription pipeline runs at an incredibly low cost — just $0.00034 per audio minute. And get this — our GPU sits idle almost half the time, meaning we’ve already got the headroom to scale without spending a single extra dollar.
We’re not just optimised. We’re over-prepared — and proud of it.
🛰️ Final Thoughts
We started with a simple goal: understand every customer conversation.
But what we built is so much more — a powerful AI engine that listens, understands, and helps Cars24 make smarter decisions at scale.
From fine-tuning Whisper to scaling annotations, from multilingual optimisation to LLM integration — this is the future of call intelligence in India.
Loved this article?
Hit the like button
Share this article
Spread the knowledge
More from the world of Cars24
Analytics should drive decisions, not describe them
How we stopped burning thirty hours a week on “what happened” and started using that time to decide the future
Building Resilient Node.js BFFs at Scale: Hard-Earned Lessons from Production
The difference between a BFF that handles 100rps and one that handles 10,000rps isn’t some magical framework.
When Voice AI Loses Track of Reality
I hope my findings shared here make a meaningful contribution and have a positive impact on how voice AI systems are designed and evaluated.